Research
통계적 학습이론 연구실의 주요 연구 분야를 소개합니다.
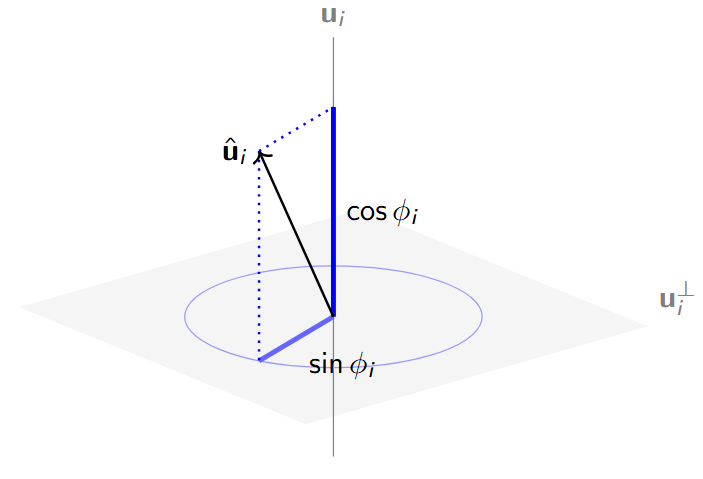
HDLSS Problem
고차원 저표본(High-Dimension, Low-Sample-Size; HDLSS) 데이터 분석은 변수의 수($p$)가 표본의 수($n$)보다 매우 큰 상황($p \gg n$)에서 발생하는 통계적 한계와 기하학적 현상을 다루는 연구 분야입니다. 기존의 다변량 통계 기법이 적용되기 어려운 이 환경에서는, 분류 시 데이터가 특정 부분공간이나 축에 집중되는 데이터 파일링(Data Piling) 현상이 관찰됩니다. 저희 연구실은 이러한 현상을 설명하고, 고차원 주성분 분석(PCA)을 통해 차원 축소의 성능을 개선하는 방법론을 연구합니다. 또한, 다중 소스로부터 수집된 복잡한 데이터 블록을 분석하기 위해 JIVE(Joint and Individual Variation Explained) 기법을 활용합니다. 이를 통해 서로 다른 데이터 간의 공통된 구조(Joint variation)와 각 데이터 고유의 변동(Individual variation)을 분리함으로써, 차원이 크고 표본 확보가 제한적인 비정형 데이터에서도 보다 안정적이고 신뢰할 수 있는 통계적 추론을 수행하고자 합니다.
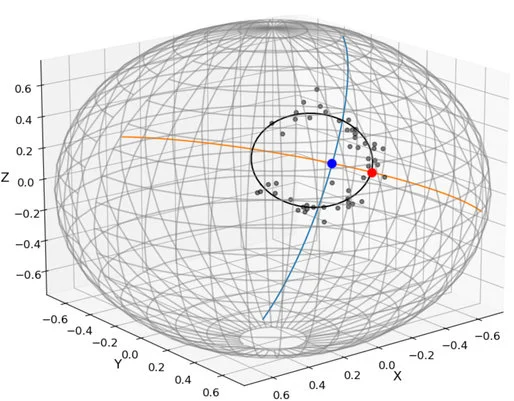
Non-Euclidean Data Analysis
현대 통계학과 데이터 과학에서는 인체 마이크로바이옴 구성 비율(Compositional data), 물체의 방향(Direction) 및 형상(Shape) 등 비유클리드(Non-Euclidean) 구조를 가진 데이터의 중요성이 점차 커지고 있습니다. 이러한 데이터는 단순체(Simplex), 구면(Sphere), 사영 공간(Projective space)과 같은 리만 다양체(Riemannian manifold) 위에 존재하는 경우가 많아, 기존의 유클리드 기반 분석법을 적용하면 거리 척도나 공분산 구조가 심각하게 왜곡될 수 있습니다. 저희 연구실은 데이터의 내재적 기하 구조를 엄밀하게 보존하고 반영하는 객체 지향 데이터 분석(Object Oriented Data Analysis; OODA) 방법론을 개발하고 있습니다. 나아가 제안된 기하학적 통계 방법론의 신뢰성과 일치성을 수학적으로 증명하여, 복잡한 비정형 데이터 분석의 새로운 표준을 제시하고자 합니다.
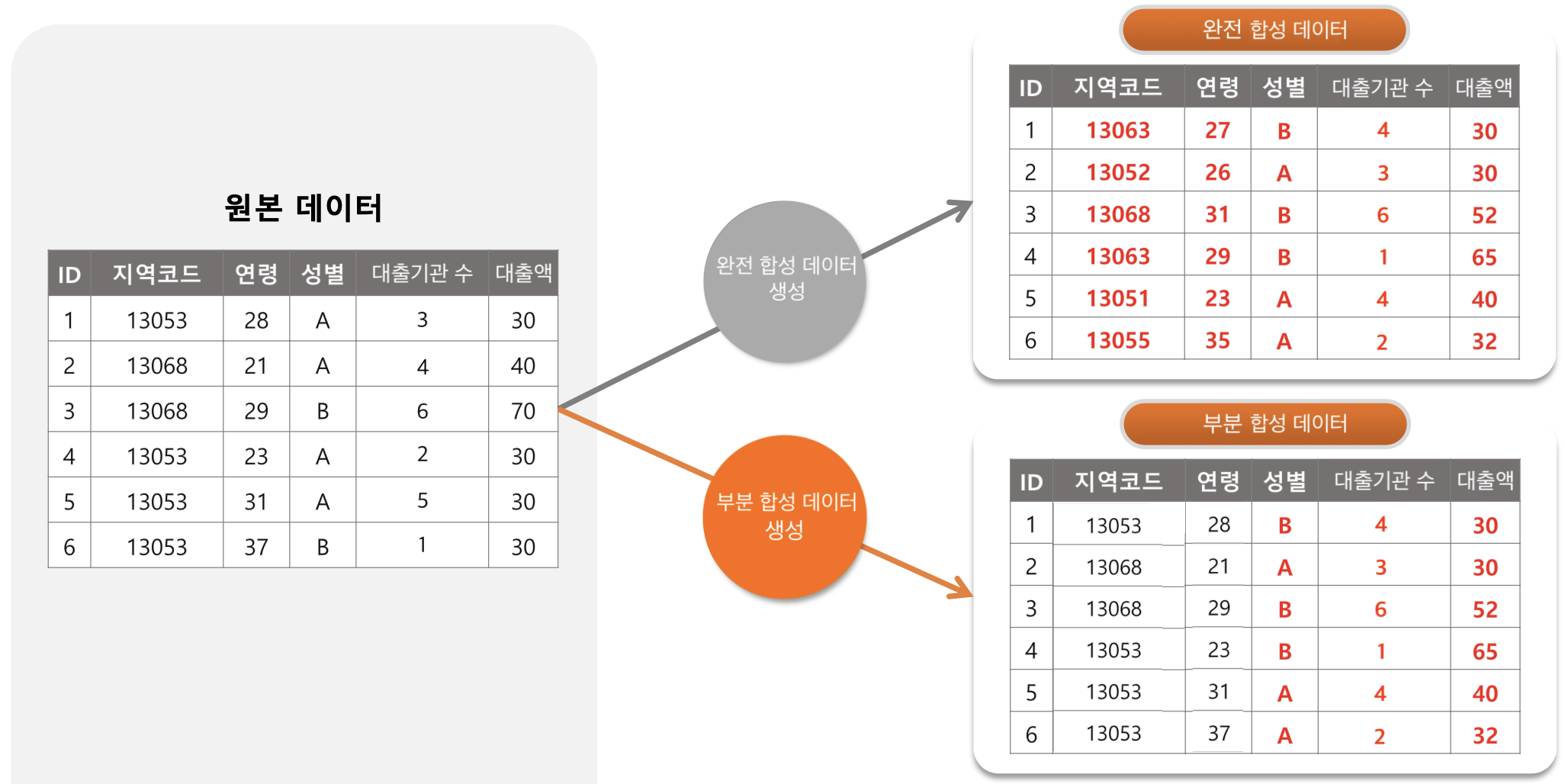
Data Privacy
빅데이터 시대에 개인정보 보호는 필수적인 윤리적, 법적 요구사항이 되었습니다. 하지만 데이터를 안전하게 보호하기 위해 변형을 가하면 통계적 유용성(utility)이 훼손되는 트레이드오프 관계에 놓이게 됩니다. 저희 연구실은 차등 정보보호(Differential Privacy) 등 엄밀한 수학적 프라이버시 기준을 만족하면서도, 원본 데이터가 가진 통계적 특성을 최대한 보존하여 유의미한 추론을 가능하게 하는 방법론을 연구합니다. 특히 고차원 다변량 자료에 대한 프라이버시 보존 추론 및 재현 데이터(Synthetic Data) 생성 기술 개발에 주력하고 있습니다.